The Web is constantly evolving and has nowadays grown into a mature self organizing system. It imitates a living organism that feeds upon information, adapts and evolves as humans and their needs evolve themselves. In its transition from a “Web of Documents” to a “Web of Linked Data” it has changed itself and our society in so many ways that it comes as no surprise it marked a major turning point in world history. In a sense, it redefined the way in which people connect, communicate and exchange knowledge.
Although it is not possible to predict in detail what its next evolutionary step is going to be, it is beneficial to look back and identify its historical curve up to this point. In this way and by observing how this event began and progressed through the last thirty years, one could shape the right expectations about its future behavior. The following sections divide web’s history up to this point into three distinct generations.
Web 1.0: The Web of Documents or Read Web
The birth of the World Wide Web took place on 1989, when Tim Berners-Lee, envisioned a global information space, where people and machines could equally exchange and exploit information rich in semantic value. Nonetheless, in its early steps the web comprised mostly of interlinked hypertext documents, (hence the Web of Documents) with the machines being merely the presenters of the latter. In fact it resembled more of a global file system, (of documents & their untyped hyperlinks being the primary objects) rather than the intended information space. A major factor that greatly influenced this matter was the absence of proper technological means, (e.g. untyped hyperlinks fail to disclose semantic relationships) to fully support the envisioned concept at that time.
This fact alone restricted the machines into simply presenting the documents and left humans to deal with their interpretation and connection. As if this was not enough, content contribution and interconnection were at least in the beginning, a privilege of a few independent web masters. Users had in their majority no actual saying but instead, their role was more of a passive consumer one, (hence the read only part). Within that context, the only available option was to acquire information from infrequently updated, static web pages of limited user interaction, (email, forums, search of info, etc).

Given these facts, it becomes obvious that despite its immediate success, Web 1.0 fell short of expectations in addressing the original vision of Tim Berners-Lee. The main reason was perhaps the early inability of humans to foresee the informational value in data contributions and of the machines to comprehend the meaning behind them. Overall, one may state that the first generation was more tailored towards passive, human consumers of information that were forced to fill in the semantic gaps themselves.
Web 2.0: The Social or Read/Write Web
Building on top of its predecessor and upon the realization that the web should be a living social creation, Web 2.0 emerged in an attempt to resolve open issues of the previous generation. Known also as the “Social Web”, this read/write, second version focused more into empowering its everyday users to create, control and share content of their own effortlessly, (multimedia, blogs, wikis, social networks, etc). In effect the aim was to overcome the limited user interaction issue of Web 1.0 and to offer a complementary, “Content Producer” role to its users. As a result Web 2.0 got quickly flooded with user generated content and that further led to an explosive growth of social networking. This new “Social Web” was all about participation, collaboration and forming communities for richer benefits and enhanced user interaction.

Nevertheless, although Web 2.0 was a giant leap forward and pointed in the right direction, it did not offer ways to administer this plethora of information, especially now that all users were at the same time potential content contributors. Thus while web content was as before comprehensible by humans, its sudden abundance rendered proper information management no longer possible without the active involvement of the machines. As soon as data contributions exceeded the consumption capabilities of human users and the informational needs of the latter increased in complexity, it became imperative to assign demanding processing and reasoning tasks to software agents and entities other than humans. Yet meaning was as in Web 1.0, still beyond their grasp especially with content that lacked some means (e.g. “semantic” and/or other structure) to reveal hidden informational parts and their relationships.
Thus, although Web 2.0 marked a transition from a “Web of Documents” to a “Web of People”, it only enabled full participation for its human users and did not manage to actively involve the machines. The latter were still unable to comprehend the meaning behind data and that is why the next evolutional step was undertaken, in the form of a “Web of Data”.
Web 3.0: The Semantic Web, (Web of Data)
The Semantic Web is all about enabling meaning hidden in the vast amounts of data on the web to become effortlessly and readily exploitable. As previously mentioned, the term exploitable in this case is not limited strictly to human consumption, but aims to gradually include any entity connected on the web. Thus, while Web 2.0 supported only collaboration between humans and the reasoning was done by the latter, this latest generation endeavours to take this a step further. It actually promotes the collaboration of “connected entities” on the web by empowering them to make meaningful content contributions, grasp the meaning behind them and collectively reason, all on the user’s behalf. Based on a, currently evolving web architecture, this generation seeks to enable entities to discover and access the “right” parts of information each time, preferably the ones of interest and being related in some way. New associations may then be made based on these relations and their significance so as to uncover even more relevant information across data sources.
This further sets the basis for rich information mashups, more fine-grained queries and at the end of the day, services that meet complex informational needs in a seamless way. In fact, it describes a transition from a “Web of People” sharing information to a “Web of Knowledge”, generated on human demand and served by the machines.

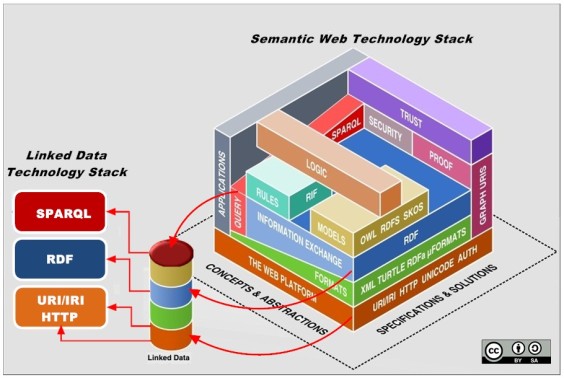
Whatever the name is, whether Semantic Web, or Web of Data, or even Web of Knowledge, the next generation is characterized by an ongoing effort to provide the kind of web architecture that supports the previously mentioned goals. Thus said, the latest web architecture is continuously evolving around a stack of already proven and emerging technological components, the “Semantic Web Stack”.